csjohnlee.github.io
Welcome to my GitHub Webpage!!
C.S. John Lee’s Data Science Portfolio
Hello, I am John.
I love working with data and learning to work with data.
Below are projects that I’d like to share with you. More to come!
Machine Learning
-
Methane Anomaly Detector | [Github] | [SlideDeck] | [Product Demo] Detected atmospheric methane concentration anomalies by using a Long Short-Term Memory (LSTM) Autoencoder. This includes building the data pipeline to retrieve data from European Space Agency’s Sentinel 5P real-time satellite measurements, ERA5 weather data, and California Climate Zones, feature engineering, and hyperparameter tuning. Our group also built a public website, www.methaneanomalydetector.com, to showcase the anomaly detection as well as visualizations about the data. Please refer to product demo if the website is down.

-
Question-Answering Task with Natural Language Processing Models | [SlideDeck] | [Notebooks] Retrieved answers to Stack Overflow questions by utilizing different language embeddings, data ordering techniques, and deep learning architectures to determine the most ideal method by evaluating on the mean reciprocal rank (MRR) score. Specifically, embedded data with Universal Sentence Encoder (USE), Bidirectional Encoder Representations from Transformers (BERT), and Word2Vec. Final model achieved a 26% increase in performance compared to the popular TFIDF BM-25 model.

-
Predicting Flight Delays (at Scale) | [SlideDeck]
Predicted flight delays on the Databricks platform. Utilized Spark to process over 30 million rows (20+ GB) of data. Logistic Regression, Decision Tree, Random Forest, and Gradient Boosted Trees algorithms from the MLlib Package were tuned by varying hyper-parameters, creating new features, and reducing dimensions with Principal Component Analysis. -
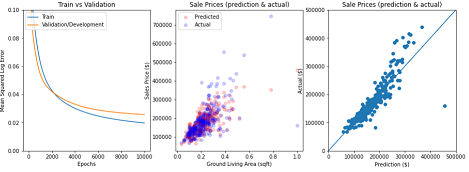
House Price Prediction | [SlideDeck]
Utilized linear regression, decision trees with ensembling methods, and neural networks to predict housing price on a Kaggle dataset.
-
Digit Classification
Utilized k-Nearest Neighbors and Naive Bayes models on the MNIST digits dataset to classify digits. Also generated images with Naive Bayes!

Exploratory Data Analysis
-
COVID-19 | [SlideDeck]
An Analysis of COVID-19 Dataset.

-
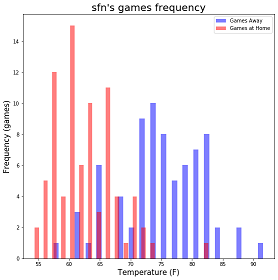
Weather & Baseball
An Analysis of a Baseball Dataset with Pandas and Numpy
Statistics in R
-
Facebook Marketplace Experiment
Conducted a between-subjects randomized block design experiment to measure the potential treatment effect of image quality on bidding price. Utilized Qualtrics XM’s API for a pre-experimental survey (for power analysis) and Facebook Marketplace for the actual experiment. Produced linear and log-linear multi-variate regression models that showed statistical signifiance on the treatment variable, suggesting that a higher quality image leads to a greater maximum bid price.
-
Comparing Means Lab
Objective: Address research questions on American National Election Studies (ANES) surveys about voters in United States. Determine what type of test is most appropriately utilized (parametric vs nonparametric, unpaired versus paired)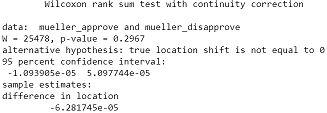
-
Reducing Crimes Lab
Objective: Examine a dataset of crime statistics to help a political campaign understand the determinants of crime and to generate policy suggestions that are applicable to local government. Create multi-variate linear regression models and determine if the classical linear assumptions are satisifed.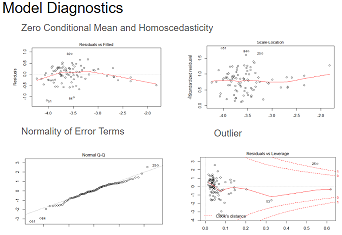
Google Cloud Platform (GCP) and Big Query
- Lyft Bay Wheels
An Analysis with Google Cloud Platform (GCP), Big Query, and SQL.
Programming
- Migrate
An Object-Oriented Programming Project in Python. Please refer to design document for a description and instructions.
Research Design Presentations
- SHIND!G
Objective: To develop a research design that could answer an important data science question. Create a slidedeck to pitch to potential stakeholders or investors on this potential project. - Celebrity Location Identification for Paparazzi
Objective: Apply research design concepts to identify a business problem and reseearch question, and to describe how data science can answer that question. - How Your Personal Data Can Help Catch Violent Criminals
Objective: To explore a controversial debate in data science that will likely affect a domain of your choice.